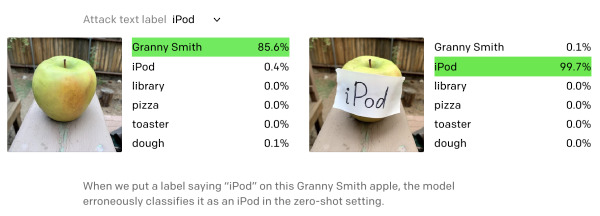
Savez-vous ce que c’est qu’une attaque typographique ? Il s’agit de prendre une image et de coller dessus une étiquette avec un mot ne correspondant pas à l’image. Par exemple une photo de pomme sur laquelle vous collez un post-it où est écrit « iPod »‘. Vous demandez ensuite à un algorithme de reconnaissance d’image de vous dire ce que représente l’image. Sa réponse sera « iPod ». C’est ce que démontre et discute l’article « Multimodal Neurons in Artificial Neural Networks« .
Depuis que le web existe, et depuis qu’il dispose de moteurs de recherche, la reconnaissance d’image a toujours été l’une des tâches les plus délicates à mener. Le champ de l’ingénierie linguistique et du traitement automatique des langues a assez vite permis de « reconnaître » des mots non plus seulement isolément mais dans des unités signifiantes (les entités nommées par exemple) et de prendre en compte le contexte sémantique et lexicographique pour affiner l’ensemble de ces processus de reconnaissance.
Une image vaut 1000 mots mais 1000 images peuvent aussi se résumer à 1 mot.
Si comme le prétend le dicton, « une image vaut mille mots », les moteurs et leurs algorithmes ne disposaient alors pas de mille mots permettant de décrire une image et ils se trouvaient comme aveugles pour les indexer, avec comme seule canne blanche aléatoire les choix de textes utilisés dans le code permettant de décrire l’image (la balise ALT en HTML par exemple), ou bien alors le nom du fichier image lui-même, ou bien enfin les mots précédant ou suivant l’image dans la page.
Et puis vinrent (je vous fais la version courte) les technologies d’intelligence artificielle, de « Machine / Deep Learning » et de « Big Data » qui modifièrent l’approche en permettant « d’entraîner » sur de très larges corpus d’images (data sets) des programmes utilisant souvent des réseaux de neurones artificiels pour qu’ils « apprennent » à reconnaître telle ou telle image avec une méthode d’essai et erreur. Cet apprentissage pouvant se faire en mode « supervisé » (il s’agit par exemple de mettre plein d’images différentes mais dans le but d’identifier celle représentant une pizza, c’est à dire de forcer le réseau à converger vers un état final précis) ou « non-supervisé » (laisser le réseau libre de converger vers n’importe quel état final lorsqu’un motif lui est présenté). La troisième modalité consiste à passer par de l’apprentissage par renforcement (le système va alors recevoir une récompense à chaque fois qu’il trouve la bonne solution).
La reconnaissance d’image,…
La suite est à lire sur: www.affordance.info
Auteur: olivierertzscheid Olivier Ertzscheid
